Shovelware: pdf2web pipeline
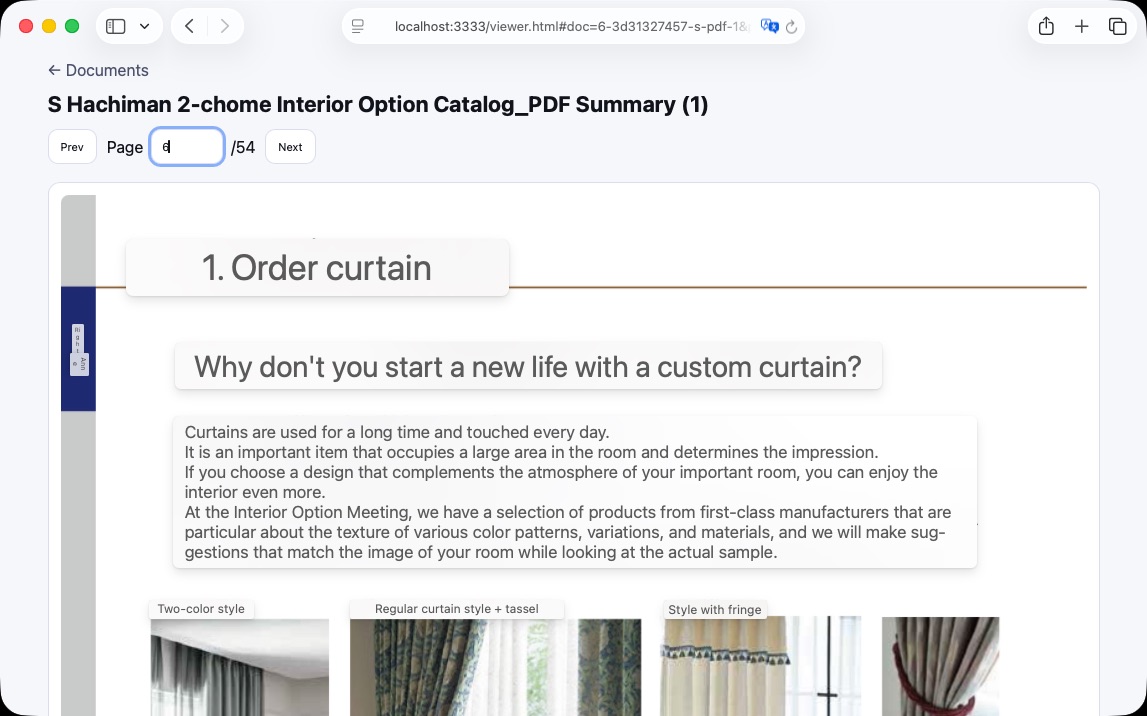
Problem: I have hundreds of pages of PDF catalogs in Japanese and no great way to translate them while retaining visual anchors. I like how Safari's built-in translate tool handles images, but it doesn't support PDFs
Solution: point Codex CLI at the directory of PDFs, tell it to rasterize every page of every doc into high-resolution images, then throw together a local webapp to navigate documents and pages. Now I can toggle Safari's built-in translation wherever I want.
Result: I'm no longer worried the curtains won't match the drapes. 💁♂️
This is the golden age of custom software if you've got an ounce of creativity in your bones.