AirPods Pro 3 are a disappointment. Seal is less reliable. They whistle from feedback when carried. 15s after popping in a second AirPod, it often still won't start playing. Reduced range. Running the microwave results in constant audio interference. Same issues on multiple pairs
Copied!
2.9k
likes
·
Glad someone else wrote this. IDGAF about macOS Tahoe app icons because they're something I see for a split-second when launching apps, but the new contextual menu icons are far more of a nuisance to trying to use apps. So much visual noise. tonsky.me/blog/tahoe-icons/
As promised last month, this issue is just oyster meat. It's a new year and as good a time as any to hit reset and get this monthly newsletter back on its preordained beginning-of-the-month-ish delivery cadence. That makes this a quick turnaround after our last issue, so there's not much new to report. Good thing I asked you all to lower your expectations!
Aaron & I kept the streak alive by executing the 2nd Annual Punsort algorithm. I think his puns got less terrible or I got better at ranking them—either way, things seemed far less contentious than in our first go-round
I did all four Disney parks in one day and live-wisped the ordeal over 12 hours, 16 rides, and 30,000 steps. If you missed my photos and videos, you'll just have to get in the habit of checking my homepage or Instagram every day, I guess! I got a couple remorseful emails from people looking to find my auto-deleting wisps/stories after they were, in fact, deleted. 💨
Becky gave me a Steam gift card for Christmas, and this humorous trailer immediately sold me on Ball x Pit. I've since played it and can confirm it to be a Good Game: part Vampire Survivors, part Plants vs. Zombies, part Breakout.
Macs have FileVault encryption enabled by default, which has always diminished their utility as home servers—if the power goes out, there goes your remote login access! They finally addressed this in macOS 26 Tahoe: inbound SSH connections following a cold boot will now unlock and finish booting my FileVault-protected Mac Studio
For the second year in a row, us kids paid a visit to dad's second-favorite spot in Walt Disney World on Christmas Day:
Fortunately, gallows humor has always played in the Searls family.
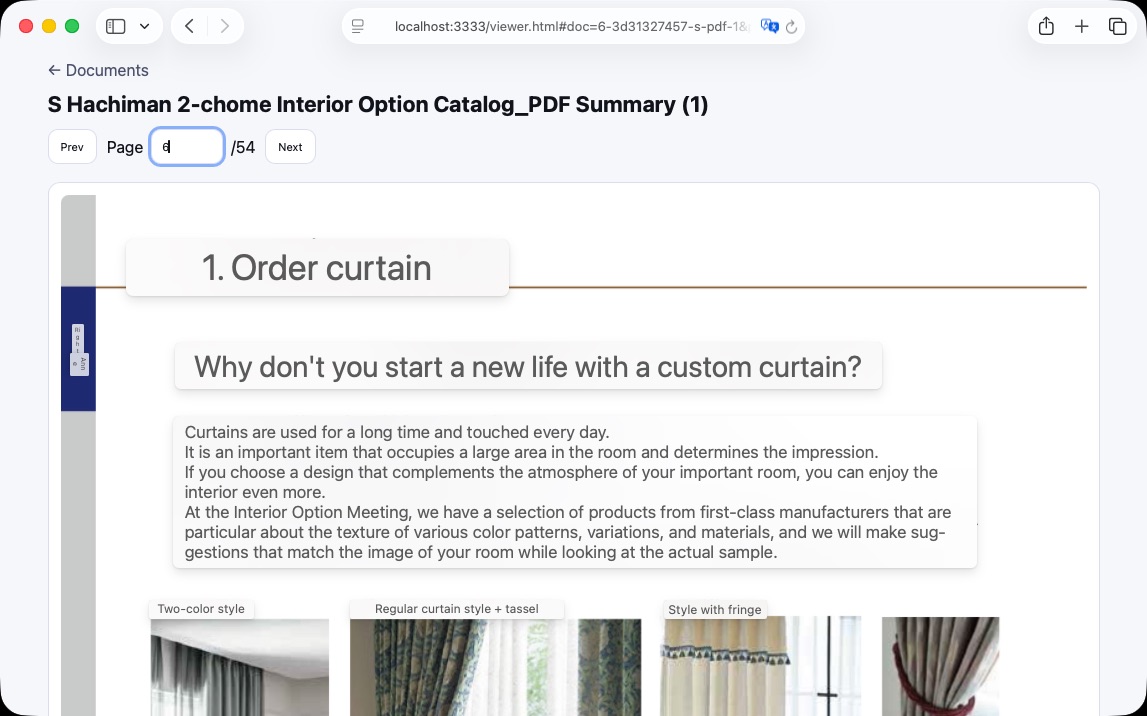
Stay tuned for next month's note, as I'll have just gotten back from the storied land of Shizuoka following the next chapter of our condo purchase journey. We're still on track to close in July, but in mid-January I have the not-technically-mandatory opportunity to pick out the curtains and the drapes at a sort of mini trade show event held by the developer. Well, curtains, yes, but also air conditioners. And tile. And how to finish the balcony. And how many mirrors we want, and where, and whether to tint them in sepia tones. And which LED mood lighting package should line the toilet. Should I pay for them to seal a brand new Japanese wood floor or is that a scammy upsell?
Reply and tell me what to do, please—the decision overload is truly overwhelming.
Anyway, the next week of my life is going to be spent poring over a dozen product catalogs. Bridging the language and cultural divide is extremely slow going. It's a good thing I failed to predict how much work this condo would turn out to be, or I'd never have gone through it. If you catch me having any fun this month, yell at me and tell me to get back to work.
Speaking of bridging language and culture, keep reading for one more stupid thing.
My most-used display has been Vision Pro ever since it launched in February 2024, but it's been used exclusively as a Mac Virtual Display. This is not only because the Mac is a real computer and visionOS is an IMAX-sized iPad, but because its software keyboard is worse than the worst iPhone keyboard to ever be released. And while I'd be happy to pack a travel keyboard, Vision Pro is already too bulky to fit in my bag. As a result, I may as well lug a real computer around with me and just use Vision Pro as a dumb display.
My second most-used display is an iPad mini, which essentially replaces my iPhone when I'm at home. It's set up to be more book-like: an iPhone stripped of any way to communicate with the outside world, with the exception of e-mail. Only problem is that when I do want to type, I'm stuck with what is probably Apple's second-worst software keyboard after visionOS.
My third most-used display is one of a handful of XR/AR glasses—I've been using the XReal Air 2, but am currently trialing the RayNeo Air 3s and Viture Luma Pro. With these, I can use output from any device straight to my eyeholes, so long as it supports DisplayPort over USB-C (e.g., iPhone, iPad, MacBook, Steam Deck). These are great, but once you pair an iPhone or iPad with a desktop-grade display, their lack of a similarly serious keyboard becomes apparent. Besides, when you've got shit on your face, guessing where touch targets are on a screen you can only see indirectly is maddening.
I'm reserving judgment (and praise) until I get my hands on this thing, but the headline features made it an insta-preorder:
Designed to be held while attached to a phone or as an independent accessory
Doubles as a MagSafe battery, so it manages to be useful even when you're not using it
Pairs with up to 3 Bluetooth devices (already bummed it's only 3…)
Little touches abound, too:
"Batwing" mode, where you can rotate the iPhone to a landscape orientation and—rather than have the display dominated by a software keyboard—actually have the full screen estate for your content while you type
It appears to have a simple sleep/wake switch, meaning iOS won't banish the software keyboard whenever it's in range
Quite a few special characters are handled by function keys
Alas, the one thing holding it back is no escape key. Not sure how I'll manage.
$70 if pre-ordered today (shipping in "Spring"), $110 after launch.
Problem: I have hundreds of pages of PDF catalogs in Japanese and no great way to translate them while retaining visual anchors. I like how Safari's built-in translate tool handles images, but it doesn't support PDFs
Solution: point Codex CLI at the directory of PDFs, tell it to rasterize every page of every doc into high-resolution images, then throw together a local webapp to navigate documents and pages. Now I can toggle Safari's built-in translation wherever I want.
Result: I'm no longer worried the curtains won't match the drapes. 💁♂️
This is the golden age of custom software if you've got an ounce of creativity in your bones.
A low stakes, immediately useful task for AI agents would be to stand in for humans in co-op games. I want to play Void Crew, but don't want to recruit friends or party with randos. Wish I could just spin-up a few artificial teammates store.steampowered.com/app/1063420/Void_Crew/
Happy New Year! Need something low-key to watch while you recover? How about a couple hours of Aaron and I shooting the shit as we look back on 2025's best and worst dad jokes in Breaking Change's 2nd annual Punsort! justin.searls.co/casts/feature-release-v48.1-2nd-annual-punsort/
Becky gave me a $100 gift card to Steam for Christmas, so for the first time in a decade I endeavored to hunt for some hidden gems in the Steam Winter Sale. I haven't even booted it up yet, but this trailer immediately convinced me to instabuy Ball x Pit.
I'm sure the game is great, but I wish more trailers were this stupid and irreverent. Gaming is a silly hobby and the best favorite game marketing isn't afraid to embrace that fact.
During the end-of-year podcasting doldrums, I'm pleased to bring you this Feature Release, in which I eschew my tradition of eschewing traditions and present a second annual sorting of the puns. As 2025 (a.k.a. Season 2) of Breaking Change comes to a close, Aaron Patterson once again joins the show to execute our latest iteration of the punsort algorithm.
If you agree, disagree, or are indifferent about where things landed, feel free to get it off your chest at podcast@searls.co.
This perfectly encapsulates the coding agent paradox. Agents make coding boring and formulaic. That some see a tragedy where others see a triumph exposed a disagreement over what coders want out of coding that didn't matter until now reddit.com/r/ClaudeAI/s/VDTxoeiBIh
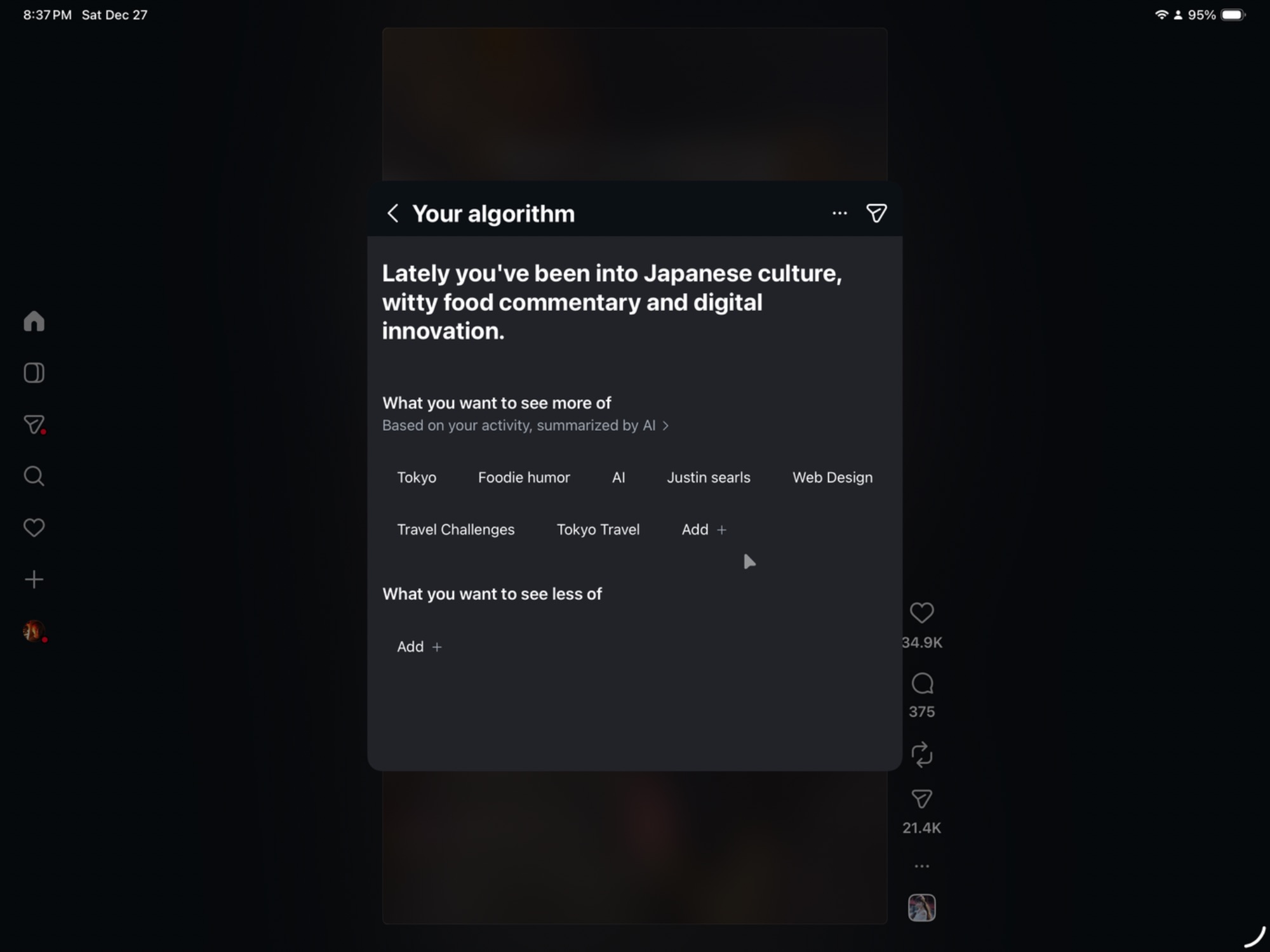
If you look closely, you'll spot that the Instagram algorithm has successfully identified my absolute number-one-with-a-bullet favorite topic. How on earth did it figure that out? My phone must be listening to me.
Braved the humanity and bolstered my immune system by subjecting myself to all four Disney Parks. 12 hours, 16 rides, and 30,000 steps. 😮💨
It turned out to be a really fun use case for my site's "Wisps" strip, which are also syndicated as Instagram stories. We have fun here.
Copied!
3.3k
likes
·
Just realized that if the children's book Cloudy with a Chance of Meatballs was localized for Japan, it could have been named, "It's Raining Men."
Who is this for? STEM majors realizing they're better off running Uber Eats?
Followed Ruby type systems for years. Spent a month of my life porting my meta-programming-heavy library Mocktail to Sorbet, only to realize zero tooling lift. No idea if it works, but I gotta say T-Ruby's pitch is the first that makes intuitive sense type-ruby.github.io
TIL if you want Safari to render 120fps, you need to go to Settings -> Advanced -> WebKit Feature Flags and TURN OFF "Prefer Page Rendering Updates near 60 fps". You can test it here—big difference! testufo.com/
Merry Christmas! I made a little present for any of my fellow Japanese learners out there. 🎁
Today I'm pleased to share this ChatGPT-powered Shortcut for Apple platforms I've been working on with you.
Here are its headlining features of the Ingest Japanese shortcut:
Render Furigana - ChatGPT tokenizes words and produces readings for kanji and okurigana, which are then assembled into an HTML page with proper <ruby> and <rt> tags (copyable as an HTML file)
Show Kana Reading - ChatGPT tokenizes the words and converts them their kana pronunciations, separating each word with a space, so you can understand word boundaries at a glance
Translate to English - Uses whatever additional context has been provided to give an accurate translation of the text
Speak Aloud - Pronounces the selected text (copyable as an audio file)
Show Definitions - Generates dictionary definitions of each distinct word found in the text, highlighting the most likely meanings based on the surrounding context (copyable as an HTML file)
It also exposes these utilities:
Copy Input - copy whatever input you passed into the shortcut to your paste buffer
Copy Last Result - copy the result of the last operation (whether a string or a file)
Provide Additional Context - explain the situation or your goal in understanding the text so that ChatGPT will provide more useful translations and definitions
Add to Word List - Appends the selection and the dictionary-form of the words contained within it to a CSV file in your iCloud Drive's Shortcuts directory (see Shortcuts/ingest-japanese/word-list.csv)
Additionally, the Ingest Image companion shortcut uses ChatGPT to extract the image and analyze the surrounding context by either:
Passing in a photo, scan, or screenshot via a share sheet
Triggering the shortcut some other way, which will capture a screenshot of your screen
In either case, it will extract the selected or primary text it finds and forward it (as well as any additional circumstantial context present in the image) to Ingest Japanese so you can study it.
I hope you check it out and find them useful in your studies!
Voters don't intuit that bond yields affect currency valuations affect foreign tourism, but Japanese populists now depend on low yields to depress the yen to maintain the supply of obnoxious foreign tourists to buoy their agenda. robinjbrooks.substack.com/p/japanese-denial-on-debt