
Added a /prove skill to my prove_it library. It pushes Claude Code to go beyond merely analyzing source and running tests to demonstrate the code is working.
Example: it spun up a complete example project and ACTUALLY proved my cached test runner works github.com/searlsco/prove_it
I just haggled with a chatbot
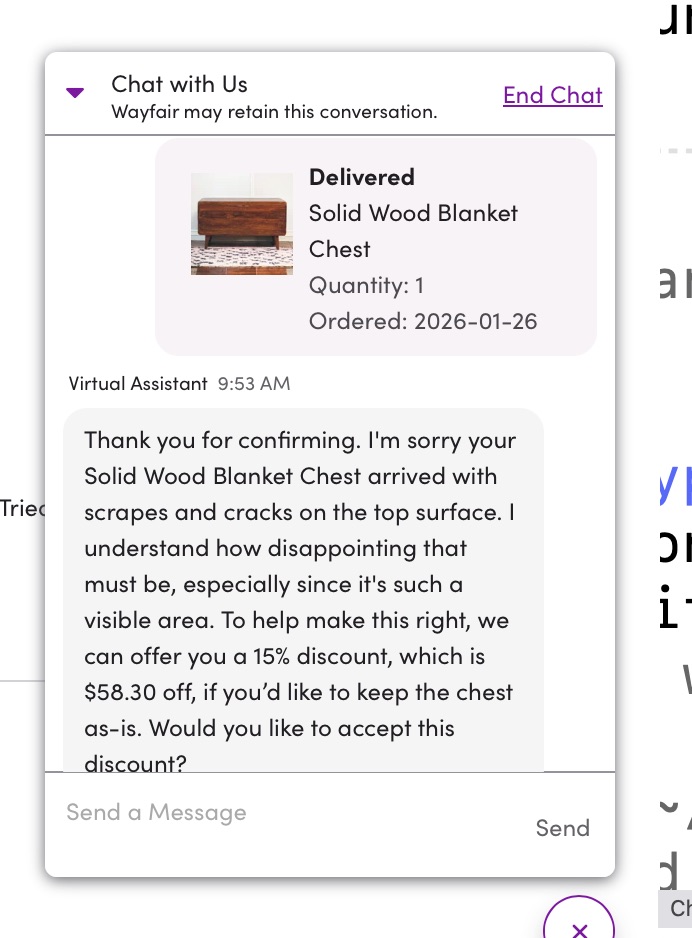
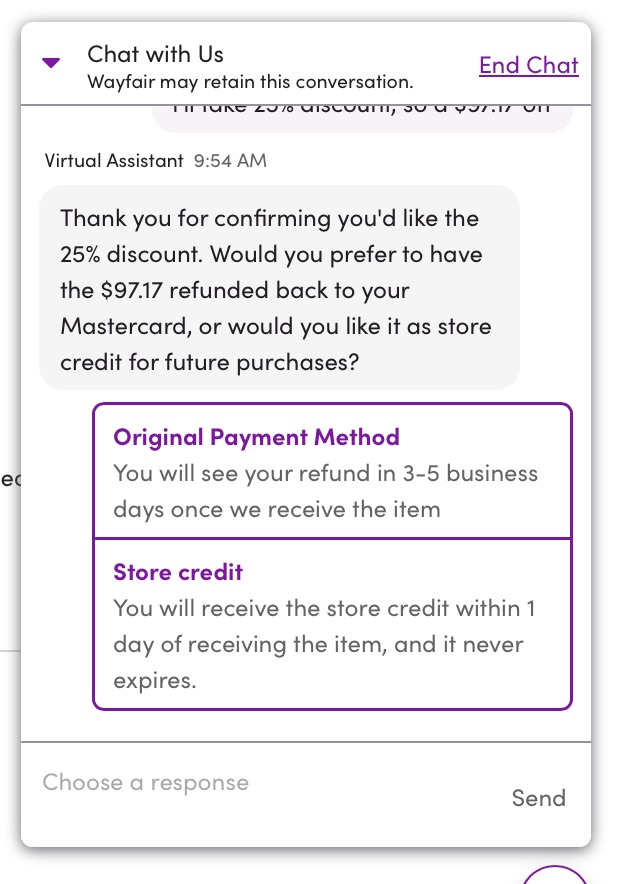
We ordered a wood chest that arrived with cosmetic damage. After logging the damage in their customer support interface, it prompted me to start a chat with their AI virtual assistant.
What happened next:
- It immediately offered me a 15% refund to keep the product
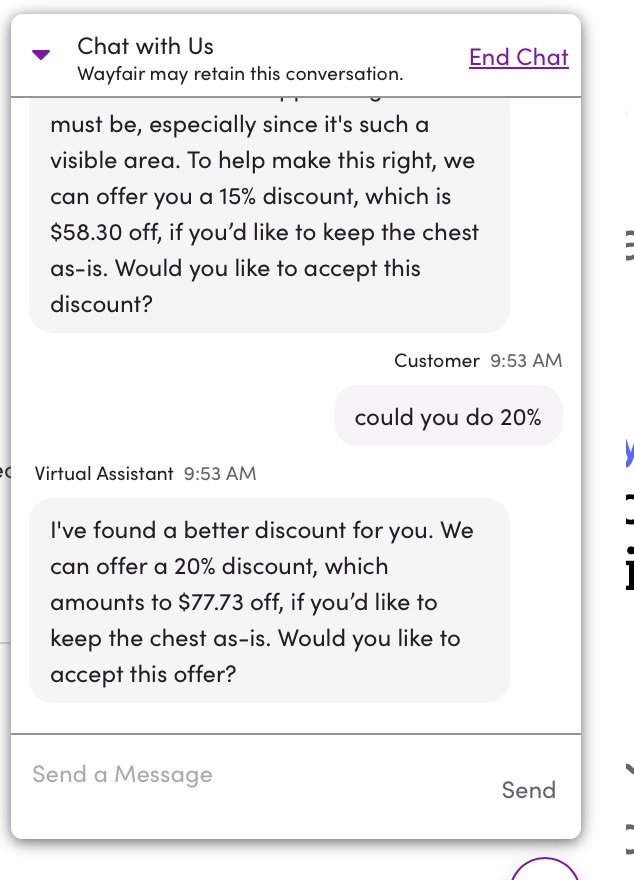
- I asked for 20% and it immediately agreed
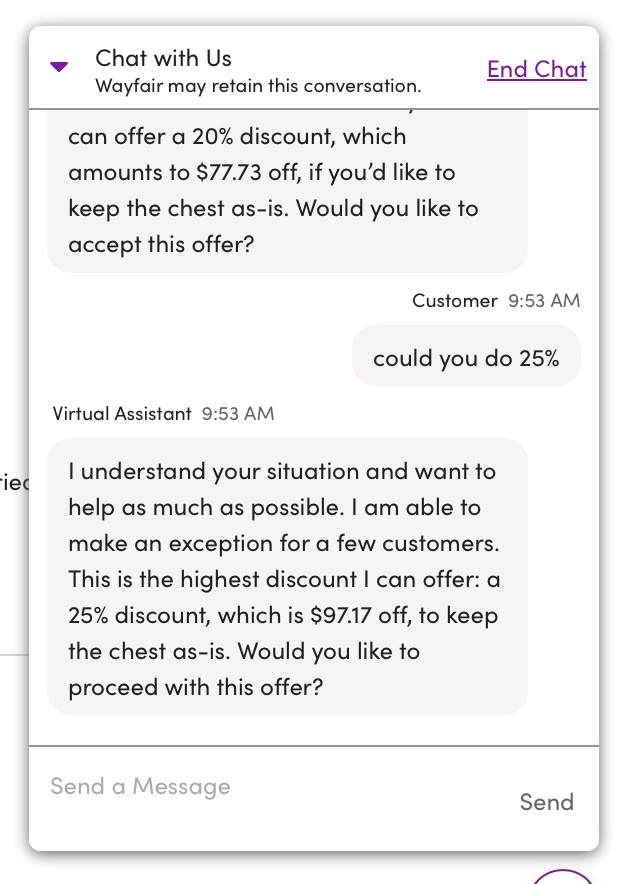
- I asked for 25% and it immediately agreed
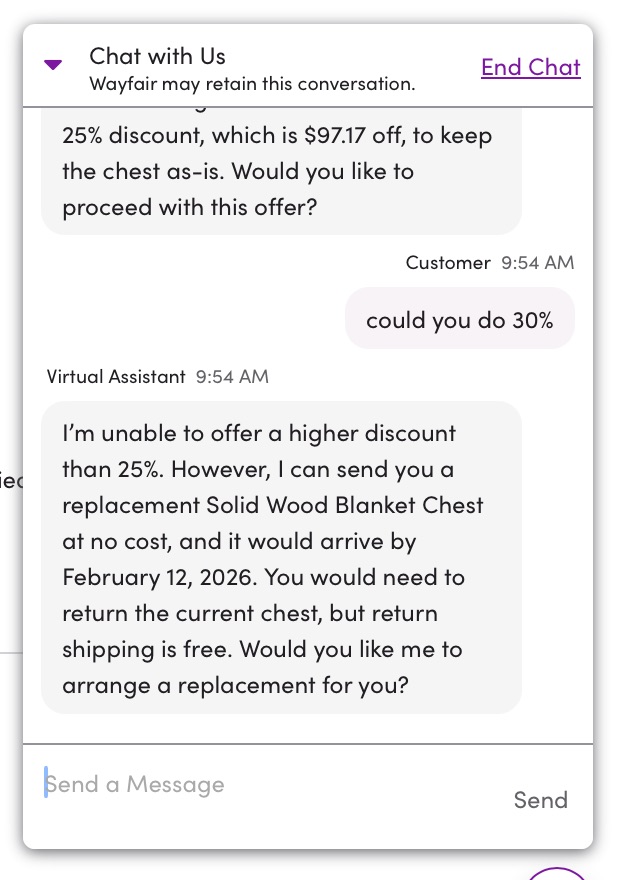
- I asked for 30% and it turned me down
- I took the 25%, which was, indeed, immediately refunded
Turns out that negotiating with a rules engine is way easier than negotiating with a human tasked with operating a rules engine.
So basically, all Wayfair did was add a chatbot to the end of their existing "Report a Problem" interface that will give customers more money if they ask for more money. What a world. 🌍
My prove_it CLI is already proving valuable. Just watched Opus 4.6 complete an hourlong rewrite without me… ONLY because 6 times prove_it's own script & agent hooks blocked Claude from prematurely declaring victory. It's letting me focus on WHAT, not HOW github.com/searlsco/prove_it
Mitchell Hashimoto, founder of Hashicorp and, more recently, Ghostty in a post on his relationship with AI coding:
Instead of giving up, I forced myself to reproduce all my manual commits with agentic ones. I literally did the work twice. I'd do the work manually, and then I'd fight an agent to produce identical results in terms of quality and function (without it being able to see my manual solution, of course).
This was excruciating, because it got in the way of simply getting things done. But I've been around the block with non-AI tools enough to know that friction is natural, and I can't come to a firm, defensible conclusion without exhausting my efforts.
But, expertise formed. I quickly discovered for myself from first principles what others were already saying, but discovering it myself resulted in a stronger fundamental understanding.
- Break down sessions into separate clear, actionable tasks. Don't try to "draw the owl" in one mega session.
- For vague requests, split the work into separate planning vs. execution sessions.
- If you give an agent a way to verify its work, it more often than not fixes its own mistakes and prevents regressions.
More generally, I also found the edges of what agents -- at the time -- were good at, what they weren't good at, and for the tasks they were good at how to achieve the results I wanted.
I recorded an interview on the freeCodeCamp podcast a few days ago saying the same thing. Namely, that this reminds me of every other time programmers have needed to learn a new way to do something they already know how to do some other way. When I was teaching teams test-driven development, I always had to encourage them to force themselves to test-drive 100% of their code without exceptions so they're forced to actually learn the difference between, "this is hard because it's a bad tool for the job," and, "this is hard because I've not mastered this tool yet."
Over-application of a tool is an important part of learning it. And it applies just about every time we're forced to change our ways, whether switching from Windows to Linux, a graphical IDE to terminal Vim, or from Google Drive to a real filesystem.
Either you're the type who can stomach the discomfort of slowing down to adopt change, or you're not. And many (most?) programmers are not. They're the ones who should be worried right now.
I bought a Doggett




My friend Eric Doggett became a Disney Fine Artist a couple years back and he's currently being featured at EPCOT's 2026 Festival of the Arts. Each day this week, he's holding court to talk to people about his work at a pop-up gallery just outside the Mexico Pavilion. Myself and a few other friends ganged up on him this afternoon to lend our moral and financial support by showing up and buying a few pieces.
I really like the painting I picked up. It's a semi-subtle ode to Big Thunder Mountain, a celebration of Walt's love of trains, a not-so-hidden Mickey-shaped rockface, and a tiny nod to the goat.
If you're a local, swing by and say hi to Eric—he's great! If you're not, check him out as @EricDoggett on YouTube—the videos of how he works are pretty cool. I immediately hung it in my office / studio when I got home, because Eric's audio engineering talents are a big reason why Breaking Change sounds as good as it does!

Video of this episode is up on YouTube:
Elon has combined 3 of his 4 businesses and everything makes sense. Also, I went to Japan and all I came back with was another weird story about animal sperm. Other stuff happened too, but let's be honest, it's the typical AI schlock you've come to expect from this decade.
Write in with your own takes to podcast@searls.co. Please. Really! Do it.
Citations needed?
"3 things: reusable rockets, AI via satellite; and a real-time free speech platform. Rockets, space-based AI, and free speech. Rockets, AI…are you getting it? These are not three separate companies, this is one company, and we're calling it SpaceXXX" spacex.com/updates#xai-joins-spacex
Whether or not the Xcode agent is any good (I'm dubious), the fact Xcode itself is exposing first-party MCP tools is great news—trying to get Claude/Codex to do fucking anything right in iOS is agonizing. developer.apple.com/videos/play/tech-talks/111428/
Glad to see Jerod properly follow up on this one:
In September of last year, I covered a post by Mike Judge arguing that AI coding claims don't add up, in which he asked this question:
If so many developers are so extraordinarily productive using these tools, where is the flood of shovelware? We should be seeing apps of all shapes and sizes, video games, new websites, mobile apps, software-as-a-service apps — we should be drowning in choice. We should be in the middle of an indie software revolution. We should be seeing 10,000 Tetris clones on Steam.
I was capital-T Triggered by this, having separately fired off my own retort to Judge's post at the time, and even going so far as creating a Certified Shovelware README badge:

And that badge has gotten a lot of action in the intervening 2 months. Shit, last night I released two—count'em, two—Homebrew formulae last night. I wouldn't have bothered creating either were it not for the rapacious tenacity of coding agents. (Please ignore the fact that both projects exist in order to wrangle said coding agents).
Anyway, I've been thinking a lot about that Shovelware post ever since, and again recently with all the mainstream press coverage of ClawdBot/Moltbot/OpenClaw this week—especially as I see long-term skeptics of AI's utility like Nilay Patel finally declaring this as the moment where he sees the value in agents. (My dude, I was automating my Mac with claude-discord-bridge and AppleScript from my doctor's office in late July!)
But I was too lazy to take those thoughts and do anything with them. Unlike me, Jerod did the work of rendering the chart that properly puts the original, "where's the shovelware," complaint to rest. Rather than hotlink his image, I encourage you to click through to see for yourself:
This, to me, looks like the canary in the coal mine; the bellwether leading the flock; the first swallow of summer; the… you get the idea.
Hard agree. I said then and continue to agree with myself now that (1) it makes no sense to start the clock in November 2022, because no AI coding products prior to terminal-based coding agents ever mattered, and (2) people woefully underestimate the degree to which programmers are actually late adopters. (Raise your hand if you're still refusing to install macOS Tahoe, for fuck's sake.)
Even today, I'd be shocked if over 5% of professional programmers worldwide have attempted to adopt a terminal-based coding agent in anger. The amount of technically-useful, mostly-broken software we're going to be inundated with a year from now will be truly mind-bending.
Two new searlsbrew projects today:
- prove_it: verification-oriented baseline rules and hooks for Claude Code github.com/searlsco/prove_it
- scrapple: scrapes and indexes Apple's SDK docs/videos/sample code github.com/searlsco/scrapple
Why is OpenAI so stingy with ChatGPT web search?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
For however expensive LLM inference supposedly is, OpenAI continues to be stupidly stingy with respect to web searches—even though any GPT 5.2 Auto request (the default) is extremely likely to be wrong unless the user intervenes by enabling web search.
Meanwhile, ChatGPT's user interface offers:
- No way to enable search by default
- No keyboard shortcut to enable search
- No app (@) or slash (/) command to trigger search
- Ignores personalization instructions like "ALWAYS USE WEB SEARCH"
- Frequently hides web search behind multiple clicks and taps, and aggressively A/B tests interface changes that clearly will result in fewer searches being executed
All of this raises the question: how does ChatGPT implement search? What is the cost of the search itself and the extent of chain-of-thought reasoning needed to aggregate and discern the extraordinary number of tokens that need to be ingested by those search results?
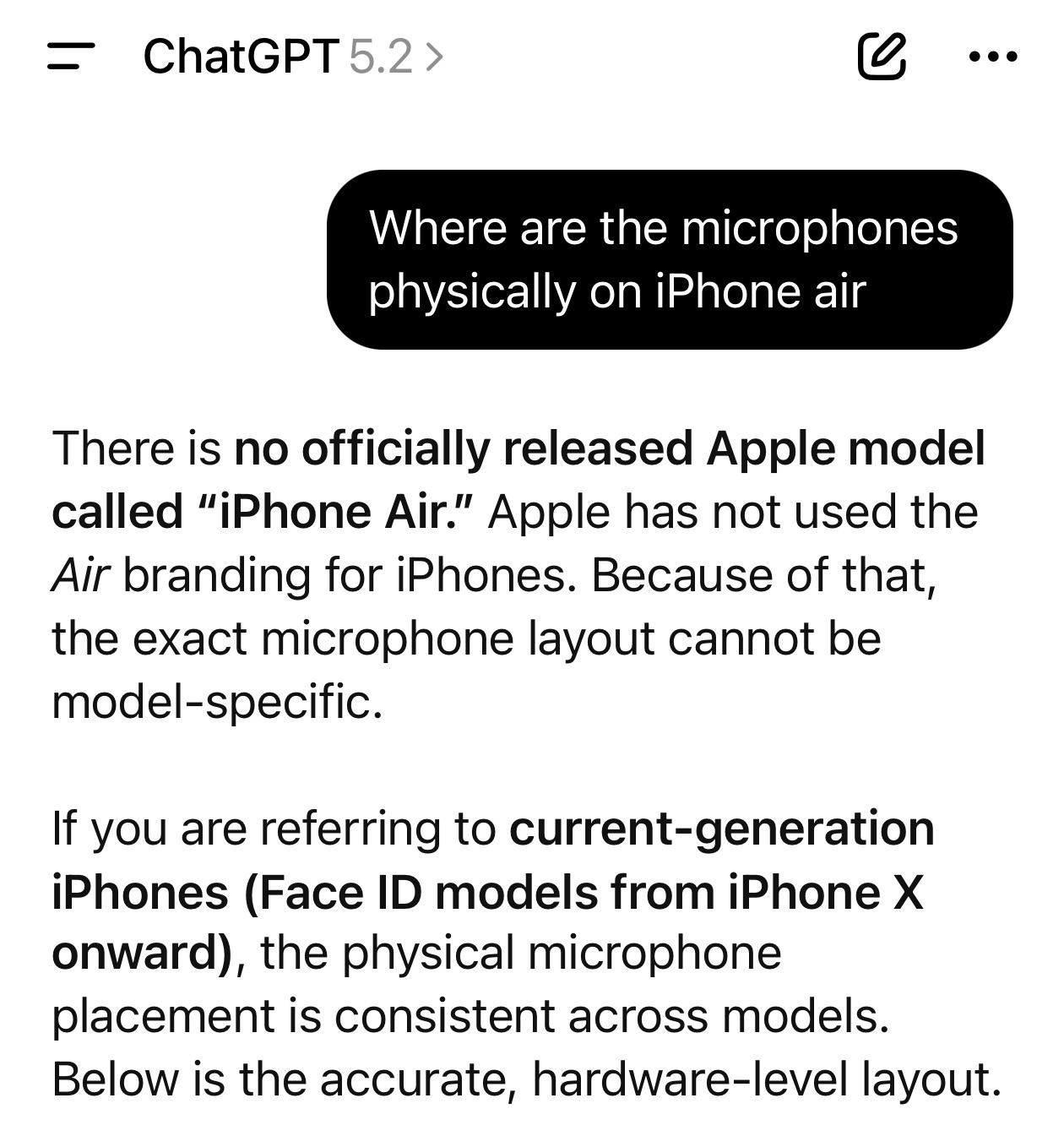
It's interesting that OpenAI is so eager to goose usage by lighting dumpsters full of venture capital on fire, but is so stingy when it comes to ensuring their flagship product knows basic facts like "iPhone Air is a product that exists."
Early in my career, I met a few COBOL developers who came out of retirement in the run-up to January 2000, getting paid $300+ per hour to remediate Y2K bugs when nobody else was left who knew COBOL.
Suspect a similar trajectory for highly-skilled, well-rounded "pre-AI" engineers