WWDC 2025 delivered on the one thing I was hoping to see from WWDC 2024: free, unlimited invocation of Apple's on-device language models by developers. It may have arrived later than I would have liked, but all it took was the first few code examples from the Platforms State of the Union presentation to convince me that the wait was worth it.
Assuming you're too busy to be bothered to watch the keynote, much less the SOTU undercard presentation, here are the four bits of Swift that have me excited to break ground on a new LLM-powered iOS app:
@Generable and @Guide annotations#Playground macroLanguageModelSession's async streamResponse functionTool interface
Here's the first snippet:
@Generable
struct Landmark {
var name: String
var continent: Continent
var journalingIdea: String
}
@Generable
enum Continent {
case africa, asia, europe, northAmerica, oceania, southAmerica
}
let session = LanguageModelSession()
let response = try await session.respond(
to: "Generate a landmark for a tourist and a journaling suggestion",
generating: Landmark.self
)
You don't have to know Swift to see why this is cool: just tack @Generable onto any struct and you can tell the LanguageModelSession to return that type. No fussing with marshalling and unmarshalling JSON. No custom error handling for when the LLM populates a given value with an unexpected type. You simply declare the type, and it becomes the framework's job to figure out how to color inside the lines.
And if you want to make sure the LLM gets the spirit of a value as well as its basic type, you can prompt it on an attribute-by-attribute basis with @Guide, as shown here:
@Generable
struct Itinerary: Equatable {
let title: String
let destinationName: String
let description: String
@Guide (description: "An explanation of how the itinerary meets user's special requests.")
let rationale: String
@Guide(description: "A list of day-by-day plans.")
@Guide(.count(3))
let days: [DayPlan]
}
Thanks to @Guide, you can name your attributes whatever you want and separately document for the LLM what those names mean for the purpose of generating values.
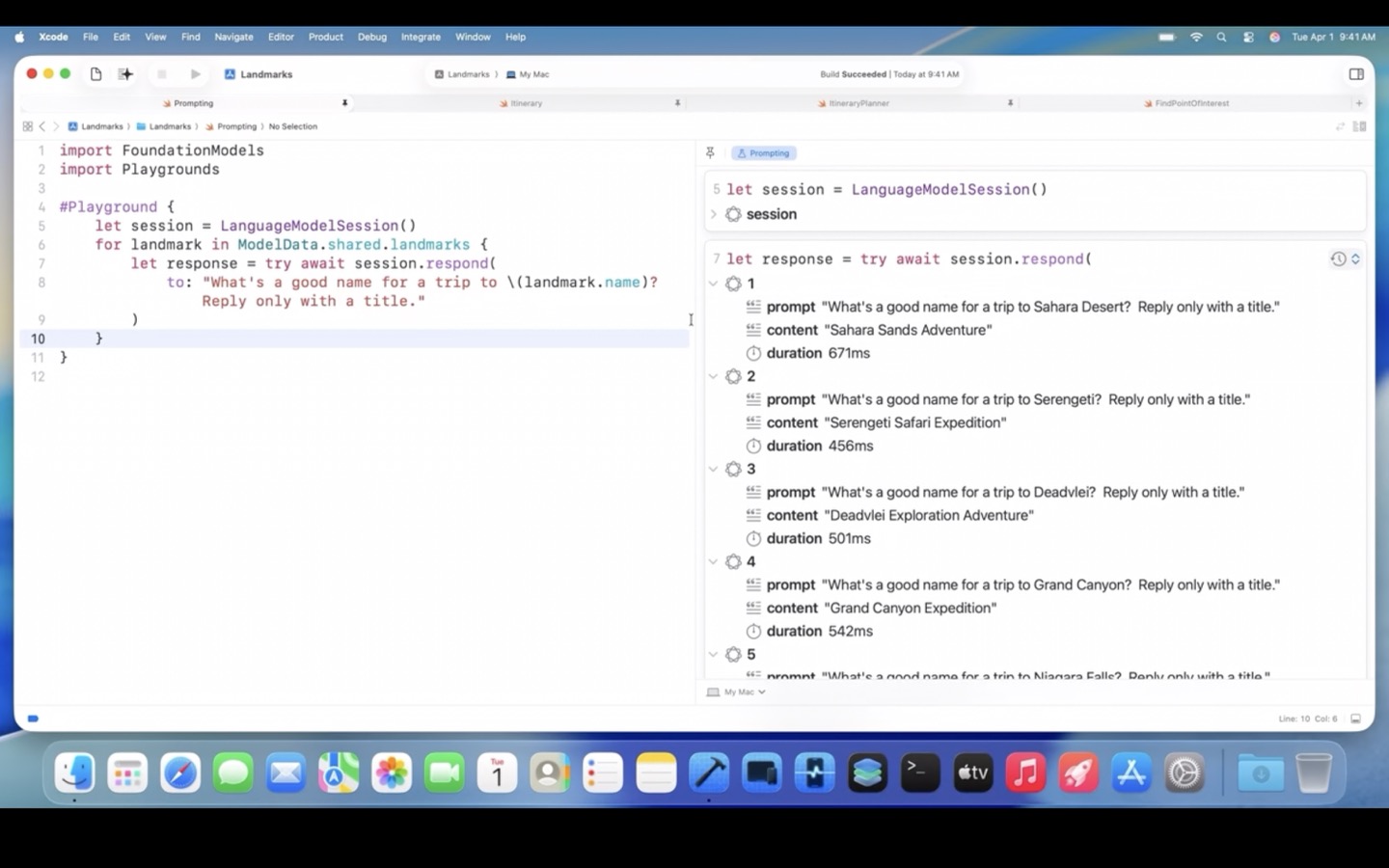
My ears perked up when the presenter Richard Wei said, "then I'm going to use the new playground macro in Xcode to preview my non-UI code." Because when I hear, "preview my non-UI code," my brain finishes the sentence with, "to get faster feedback." Seeing magic happen in your app's UI is great, but if going end-to-end to the UI is your only mechanism for getting any feedback from the system at all, forward progress will be unacceptably slow.
Automated tests are one way of getting faster feedback. Working in a REPL is another. Defining a #Playground inside a code listing is now a third tool in that toolbox.
Here's what it might look like:
#Playground {
let session = LanguageModelSession()
for landmark in ModelData.shared.landmarks {
let response = try await session.respond(
to: "What's a good name for a trip to \(landmark.name)?
Reply only with a title."
)
}
}
Which brings up a split view with an interactive set of LLM results, one for each landmark in the set of sample data:
Watch the presentation and skip ahead to 23:27 to see it in action.
Users were reasonably mesmerized when they first saw ChatGPT stream its textual responses as it plopped one word in front of another in real-time. In a world of loading screens and all-at-once responses, it was one of the reasons that the current crop of AI assistants immediately felt so life-like. ("The computer is typing—just like me!")
So, naturally, in addition to being able to await a big-bang respond request, Apple's new LanguageModelSession also provides an async streamResponse function, which looks like this:
let stream = session.streamResponse(generating: Itinerary.self) {
"Generate a \(dayCount)-day itinerary to \(landmark.name). Give it a fun title!"
}
for try await partialItinerary in stream {
itinerary = partialItinerary
}
The fascinating bit—and what sets this apart from mere text streaming—is that by simply re-assigning the itinerary to the streamed-in partialItinerary, the user interface is able to recompose complex views incrementally. So now, instead of some plain boring text streaming into a chat window, multiple complex UI elements can cohere before your eyes. Which UI elements? Whichever ones you've designed to be driven by the @Generable structs you've demanded the LLM provide. This is where it all comes together:
Scrub to 25:29 in the video and watch this in action (and then re-watch it in slow motion). As a web developer, I can only imagine how many dozens of hours of painstaking debugging it would take me to approximate this effect in JavaScript—only for it to still be hopelessly broken on slow devices and unreliable networks. If this API actually works as well as the demo suggests, then Apple's Foundation Models framework is seriously looking to cash some of the checks Apple wrote over a decade ago when it introduced Swift and more recently, SwiftUI.
When the rumors were finally coalescing around the notion that Apple was going to allow developers to invoke its models on device, I was excited but skeptical. On device meant it would be free and work offline—both of which, great—but how would I handle cases where I needed to search the web or hit an API?
It didn't even occur to me that Apple would be ready to introduce something akin to Model Context Protocol (which Anthropic didn't even coin until last November!), much less the paradigm of the LLM as an agent calling upon a discrete set of tools able to do more than merely generate text and images.
And yet, that's exactly what they did! The Tool interface, in a slide:
public protocol Tool: Sendable {
associatedtype Arguments
var name: String { get }
var description: String { get }
func call(arguments: Arguments) async throws -> ToolOutput
}
And what a Tool that calls out to MapKit to search for points of interest might look like:
import FoundationModels
import MapKit
struct FindPointOfInterestTool: Tool {
let name = "findPointOfInterest"
let description = "Finds a point of interest for a landmark."
let landmark: Landmark
@Generable
enum Category: String, CaseIterable {
case restaurant
case campground
case hotel
case nationalMonument
}
@Generable
struct Arguments {
@Guide(description: "This is the type of destination to look up for.")
let pointOfInterest: Category
@Guide(description: "The natural language query of what to search for.")
let naturalLanguageQuery: String
}
func call(arguments: Arguments) async throws -> ToolOutput {}
private func findMapItems(nearby location: CLLocationCoordinate2D,
arguments: Arguments) async throws -> [MKMapItem] {}
}
And all it takes to pass that tool to a LanguageModelSession constructor:
self.session = LanguageModelSession(
tools: [FindPointOfInterestTool(landmark: landmark)]
)
That's it! The LLM can now reach for and invoke whatever Swift code you want.
I'm excited about this stuff, because—even though I was bummed out that none of this came last year—what Apple announced this week couldn't have been released a year ago, because basic concepts like agents invoking tools didn't exist a year ago. The ideas themselves needed more time in the oven. And because Apple bided its time, version one of its Foundation Models framework is looking like a pretty robust initial release and a great starting point from which to build a new app.
It's possible you skimmed this post and are nevertheless not excited. Maybe you follow AI stuff really closely and all of these APIs are old hat to you by now. That's a completely valid reaction. But the thing that's going on here that's significant is not that Apple put out an API that kinda sorta looks like the state of the art as of two or three months ago, it's that this API sits on top of a strongly-typed language and a reactive, declarative UI framework that can take full advantage of generative AI in a way web applications simply can't—at least not without a hobbled-together collection of unrelated dependencies and mountains of glue code.
Oh, and while every other app under the sun is trying to figure out how to reckon with the unbounded costs that come with "AI" translating to "call out to a hilariously-expensive API endpoints", all of Apple's stuff is completely free for developers. I know a lot of developers are pissed at Apple right now, but I can't think of another moment in time when Apple made such a compelling technical case for building on its platforms specifically and at the exclusion of cross-compiled, multi-platform toolkits like Electron or React Native.
And now, if you'll excuse me, I'm going to go install some betas and watch my unusually sunny disposition turn on a dime. 🤞















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}